A 3D-s grafikus kártyák működéséhez szükséges hardverfeltételek
Az elmúlt évtizedben a számítógépes grafika az informatika legdinamikusabban fejlődő ágává vált. Egyre több és nagyobb teljesítményű hardvereszközt fejlesztettek ki a grafikus alkalmazások számára, az eszközöket egyre több cég gyártotta. Emiatt a grafikus szoftvereket kezdetben eszközfüggően kellett programozni. Ez azonban nem felelt meg a körszerű igényeknek, ezért szabványosítási folyamat vált szükségessé. A szabványosítás következtében a hardveregységeket továbbra is több cég gyártja, azonban azok a szabvány használata miatt nem térnek el egymástól. A szoftverek esetében is léteznek szabványok. Így a szabvány szerint készített szoftver bármelyik gyártó által gyártott hardveren gond nélkül futtatható. A következőkben részletezem a háromdimenziós gyorsítású grafikus kártyák működéséhez szükséges hardveregységeket és a grafikai megjelenítéshez nélkülözhetetlen programcsomagokat.
Hardveregységek
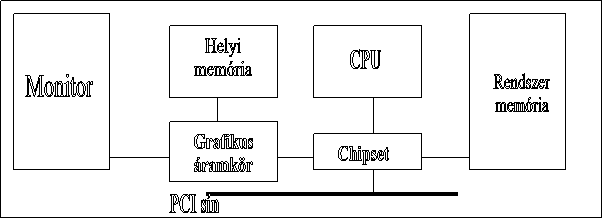
1.Buszrendszer (AGP)
Az AGP (Accelerated Graphics Port, gyorsított grafikus port) a jelenlegi 3D-s videokártyák grafikus portja. Elméletileg 4x gyorsabb a PCI sínnél. Mivel a 3D-s renderelés évről-évre több memóriát igényelt, a grafikus kártyák frame bufferének memóriakapacitása egyre kevésbé volt elég. Ezért a RAM-ot használjuk fel az egyre inkább fotorealisztikussá váló grafikus megjelenítéshez. Ez azért is jobb megoldás mivel a frame buffernek alkalmas memória sokkal drágább a központi tár RAM moduljánál. Másik mód a gyorsabb működés eléréséhez, hogy a kártya tartalmaz egy kitüntetett szerepű portot, melyen közvetlenül, késleltető elemek közbeiktatása nélkül képes elérni a memóriát és a processzort.
10.ábra: AGP felépítése
PCI sínnel szemben párhuzamos (pipeline) művelet végrehajtásra képes. A cím és az adat nincs multiplexelve és a memória-olvasáson és íráson kívül nincs más I/O művelet. A PCI sín nem alkalmaz prioritási sorrendet, míg az AGP magas/alacsony prioritású sorokat használ.
Maximum 533 Mbájt/s átviteli sebességet képes elérni. Ezt egy ún. DIME (Direct Memory Execute, direkt memória végrehajtás) technikával valósítja meg.
Amelynek az a lényege, hogy a nagy méretű képeket a rendszer az AGP rendszermemóriában, a RAM-ban tárolja. A gyors kiolvasáshoz szükséges a közvetlen elérése a RAM-nak. A kiolvasás során a képek digitális leképezései (textúrák) átkerülnek a kártyán lévő átmeneti tárolóba. Ezek mind videómemóriák, amelyek sebessége még az SDRAM-nál is nagyobb, és lehetőség van a memória egyidejű írására és olvasására is. Vagyis a sebesség megduplázódik a hagyományos memóriákhoz képest. A memóriába történő írás ennek az ellenkező folyamata. A chip azokat a képeket, melyek nem férnek el a saját memóriájába, a CPU megkerülésével közvetlenül a RAM-ba tárolja. Ha szükséges innen bármikor előhívhatja.
Az AGP 1.0 után került kifejlesztésre a 2.0 és a 3.0. A 3.0 a legújabb és valószínűleg egyben az utolsó AGP szabvány is.
Az AGP 3.0 támogatja a hardware-enforced cache coherency-t (cache-ben adatok összetartozásának hardveres erőltetése), amellyel kideríthető, és utána kijavítható az esetleges bithiba a cache-ben. Igazából ez 2 szinten történik. AGP apertúrán belül és azon kívül. Az AGP apertúra a rendszermemóriából lefoglalt rész textúra tárolására. Ezen memóriaterület virtuális címet kap, amelyet GART (Graphics Aperture RE-Map Table) segítségével lehet visszavezetni a valós címre. Az AGP apertúrán kívüli részen a cache adatainak össze kell tartozniuk, az alaplap chipsetjének ezt meg kell követelnie. Az AGP apertúrán belül az összetartozás nem kötelező, csak lehetőség, a driver szoftveres támogatását igényli. Ez az újítás mindenképpen figyelemreméltó és hasznos volt véleményem szerint, de valószínűleg csak a felsőkategóriás videokártyáknál valósul meg. Mert a mai videokártyák integrált memóriájának mérete elég nagy ahhoz, hogy ne legyen szükség a rendszermemóriára, másrészt a folyamatos hibakeresés ront a teljesítményen. Ennek mértékéről annyit ír az AGP 3.0 specifikációja, hogy platformonként változó. Szintén érdekes újítás, ami szintén csak a profi felhasználókat érinti, az egyidejű adatfolyam támogatása. Az AGP aszinkron szabványnak készült, ami azt jelenti, hogy spórol a sávszélességgel részleges terhelés esetén, teljes kihasználtság alatt azonban nem lesz egységes az adat, azaz a folyamatos áramlása kezelhetetlen. Az AGP 3.0 szinkron adatátvitele fix késleltetést határoz meg 2 adattovábbítás között. Mivel a real-time elvárások évről-évre nőnek ezért a szinkron átvitel jelentősége is nő. 3D-s alkalmazások nem nyernek ebből semmit, azonban a teljes képernyős videók igen.
A legfontosabb újítás a több AGP port támogatása. Így nyitva áll az út az alaplapgyártók előtt a két, vagy akár több AGP port támogatása. Jelenleg, ha több kijelzőt akarunk használni, mint amennyit az AGP-s videokártya támogat, akkor kénytelenek vagyunk egy PCI-os videokártyát is betenni mellé. Ez viszont jelentősen csökkenti a rendszer teljesítményét, ráadásul a 3 kijelzőt támogató Matrox Partelia teljesítménye igencsak hagy kívánni valót maga után. Bizonyos körülmények között pedig 2 kijelző használata egy AGP-s kártya esetén is komoly teljesítménycsökkenést eredményezhet. Nem kell a teljesítmény és a kijelzők száma között választani. Többprocesszoros rendszereknél szintén nagyon jól jöhet a több AGP-s slot, ugyanis lehetőség nyílik arra, hogy minden processzorhoz külön kártya tartozzon, így az AGP busz nem lesz szűk keresztmetszet. Ezen kívül minden processzorhoz külön AGP apertúra és GART (Graphics Aperture RE-Map Table) tartozhat, így elkerülhetőek az ütközések és lelassulások.
A GART-ot is felülvizsgálták és optimalizálták egy kicsit. Több részre osztott apertúrát támogat, így GTLB (Graphics Translation Lookaside Buffers) is gyorsíthatja az átvitelt. A GTLB-k kicsi, de nagyon gyors bufferek, amik eddig csak mikroprocesszorok (CPU,GPU) esetén használtak. Feladata a megfelelő apertúra lap a rendszermemóriában történő keresésének gyorsítása. A memória helyeket nagy táblákból olvassa ki. Igazából a GTLB-k nagyon hasonlóak a GART-hoz, de az AGP vezérlő definiálja őket, nem a driver, ezáltal sokkal gyorsabbak.
Az AGP 3.0 (8x) a 2 legszembetűnőbb változás az AGP 2.0(4x) szabvánnyal szemben a működési feszültséget és a sávszélességet érinti.
Az elméleti maximális sávszélesség a videokártya és a rendszermemória között megduplázódott 1,06 GB/s-ról 2,12 GB/s-ra. Azonban meg kell jegyezni, hogy még az 1,06 GB/s sincs kihasználva, ráadásul a grafikus kártyák memóriaméretének növekedésének következtében még kevesebbet számít.
|
Buszrendszer |
Működési |
Sávszélesség |
Adatátvitel |
|
|
frekvencia (MHz) |
sebessége (MHz) |
MB/s |
|
PCI busz |
33 |
33 |
133 |
|
PCI 2.1 busz |
66 |
66 |
266 |
|
AGP 1x |
66 |
66 |
266 |
|
AGP 2x |
66 |
133 |
533 |
|
AGP 4x |
66 |
266 |
1024 |
|
AGP 8x |
66 |
512 |
2048 |
11. ábra: AGP portok jellemzői
A feszültség 1,5V-ról 0,8V-ra csökkent, ami igen tekintélyes 47%-os csökkenés, bár meg kell említeni azt is, hogy a legutóbbi váltáskor 55%-os(3,3V-ról 1,5V-ra csökkentéskor) is volt.
Az AGP 2.0 szabvány nem kötelezi a gyártókat az eredeti 3.3V-os kártyák támogatására, de lehetőséget adott univerzális alaplapok gyártására is, amely 3.3V-os és 1,5V-os technológiát is támogatta. Azonban a gyártók többsége felhagyott (gazdasági racionalitásokat is figyelembe véve) a 3.3V-os kártyát támogató alaplapok gyártásával, mivel úgy gondolták, hogy nincs szükség a támogatásukra. Néhány videokártya gyártó viszont AGP 2.0 kompatibilisnek hirdette termékét, így mikor a gyanútlan felhasználó belehelyezte gépébe az újonnan vásárolt videokártyáját az 1.5V-os alaplapba kellemetlen meglepetés érte, elfüstölt az alaplap, kártya. Az AGP 3.0 nem hozott sok újítást egy átlagos felhasználónak, de igazából nem is nagyon volt min változtatni. Elsősorban a professzionális felhasználóknak nyújt érdekes, izgalmas újdonságokat.
2. 3D utasításkészlettel rendelkező processzorok
A 3D megjelenítés és képfeldolgozás igényei miatt kellett a hagyományos x86-os architektúrát új utasításokkal kiegészíteni. Az x86 architektúra hagyományos utasításaival a számítógép egyetlen utasításfolyammal egyetlen adatfolyamot dolgoz fel. Az ilyen típusú architektúrát SISD (Single Instruction Stream Single Data Stream ) architektúrájúnak nevezzük. Ilyen felépítésűek voltak a Neumann elvű gépektől kezdve a Pentium I-es gépek többsége, egészen a Pentium MMX-ig.
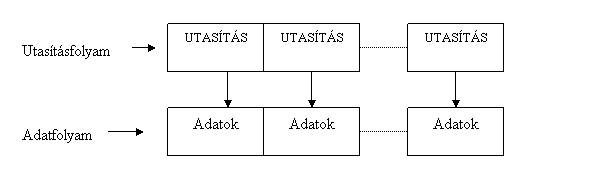
12. ábra: SISD architektúra működése
A multimédia-alkalmazásokra, vagyis a kép- és hangfeldolgozásra azonban az a jellemző, hogy viszonylag nagy mennyiségű adaton kell ugyanazt a műveletet elvégezni. A SIMD (Single Instruction Stream Multiple Data Stream) típusú számítógép egyetlen utasításfolyammal többszörös adatfolyamot dolgoz fel. Több párhuzamos, egyidejű működésre képes műveletvégző egységet tartalmaznak. Ezek a számítógépek vektorműveletek végrehajtására képesek. Ezeket az utasításokat gépi utasításszinten hajtják végre.
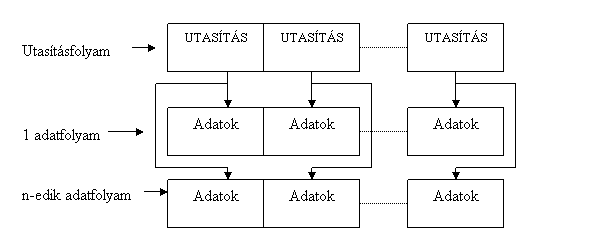
13. ábra: SIMD számítógép működése
A processzorok által nyújtott támogatásokat minden mai processzorgyártó beépíti processzoraiba. Azonban, ahogy egyre növekszik a processzorok teljesítménye, úgy tudnak a gyártók egyre többet tudó támogatásokat beépíteni. Ezek aztán az alaptámogatások neveit kapják csak kibővítve (SSE2, SSE3, Professional, stb.).
MMX
Az egyetlen olyan SIMD kiegészítés mely minden x86 típusban megtalálható. Az MMX processzorok csak a multimédiás képfeldolgozást gyorsítják, azonban ennek előfeltétele, hogy a grafikus szoftver optimalizálva legyen rá.
1997 elején az Intel a Pentiumban vezette be az MMX (Multimedia Extension) utasításkiegészítést, amit minden azóta piacra dobott processzorába beépített.
48 új utasítással és 8 új, 64 bites MMX regiszterrel (MM0-MM7) bővítették ki az utasításkészletet. A regiszterek 4 új adatformátumot fogadhatnak: nyolc 8-bites (Packed byte), vagy négy 16-bites (Packed word), vagy két 32-bites (Packed doubleword), vagy egy 64-bites (Quadword) adatot. Az MMX utasítások ugyanahhoz a művelethez minden adatformátumban külön utasítást használnak.
Az MMX bevezetett egy új eredménykezelést is. Ha az összeadás vagy szorzás eredményeként kapott szám túl nagy, vagyis nem fér el a regiszterben, akkor a szokásos esetben a legnagyobb helyiértékű bit feletti szám kicsordul a regiszterből. Erről a processzor figyelmeztetést küld, és a kicsordult bit figyelembevételével helyes lesz az eredmény. Ennek az ellenkezője az alulcsordulás. A kivonás vagy osztás után az eredmény túl kicsi, az előjel nélküli számok (pozitív számok) körében kisebb nullánál, az előjeles számok (negatív számok) körében, pedig nagyobb a regiszterben tárolható legnagyobb negatív számnál. Ez a színkezelésben lehet hasznos, mert a megjeleníthető legvilágosabb, illetve legsötétebb szín elérése után már lényegtelen a végeredmény értéke.
Az MMX és a lebegőpontos utasítások nem keverhetők, vagyis lebegőpontos utasítás kiadása előtt az MMX regiszterek tartalmát a memóriába kell menteni, és ugyanez a teendő a lebegőpontos regisztereknek kiadandó MMX-utasítások előtt.
Az MMX adattípusai csak egészszám típusok, főleg felületkitöltésre, pontképkezelésre, textúramódosításra használhatók. A lebegőpontos számok, vagyis a törtrészt is tartalmazó számok SIMD kezeléséhez az AMD a 3DNow! Utasításkészlet bővítést fejlesztette ki, az Intel pedig az SSE-t (Streaming SIMD Extension).
3DNow!
Az AMD 1998 nyarán jelentette be K6-2 processzorainak megjelentetésével ezt a kiegészítést. 21 új utasítást tartalmazott. A 3DNow! Felgyorsítja a bonyolult 3D képműveleteket, és javítja a hangtömörítést.
Nem vezetett be új regisztereket, a 64-bites MMX-regisztereket használja egy új, lebegőpontos SIMD adattípussal. Két 32-bites (23-bites alap, 8-bites kitevő, 1 bit előjel) szabványos előjeles, egyszeres pontosságú lebegőpontos számot helyez el a 64 bites regiszterben, vagyis kétszeresére növelheti az ilyen számokkal végzett műveletek sebességét.
Komoly kritika érte amiatt, hogy az összes SIMD utasítás az Intel által nem használt 0F bájtokkal kezdődik, és a tényleges műveleti kód az utasítás legutolsó bájtja. A kompatibilitási gondok elkerülése miatt vált ilyenné, de nagy hibája, hogy a processzor ütemezője csak az utasítást alkotó összes bájt betöltése után képes átadni azt a megfelelő műveletvégző egységnek.
A 21 3DNow! Utasítás közül az egyik, a PREFETCH nincs közvetlen kapcsolatban a SIMD műveletekkel: ezzel előre be lehet kérni az adatokat a processzor elsődleges (L1) adatgyorsítótárába. Ezzel elérhető, hogy ha majd szükség lesz az adatra, ne kelljen megvárni, míg megérkezik a memóriából.
A programozó így előkészülhet a gyorsnak szánt rutinok végrehajtására. A PREFETCH utasítás egyszerre egy gyorsítótár sort olvas be az L1 gyorsítótárba.
Van még egy utasítás, amely nincs közvetlen kapcsolatban a SIMD műveletekkel. Ez az MMX-es EMMS utasítás alternatívája FEMMS (Fast EMMS) néven, és az átállási késleltetést hivatott megoldani.
Az AMD az Athlon XP-k megjelenésekor a 24 új utasítás közül 5 lebegőpontos számokkal, 12 pedig egész számokkal végez műveletet, vagyis az MMX továbbfejlesztése. A PREFETCH utasításban már az is megadható, hogy melyik gyorsítótárba hívódjék be előre az adat (L1?,L2?,vagy mindkettőbe?). Az adatgyorsítótár azokat az adatokat tartalmazza, amelyeket egyszer már bekért a processzor, illetve azokat, amelyeket a programozó kért be a PREFETCH utasítással. Alaphelyzetben az adatok memóriába írásakor a gyorsítótárba is bekerülnek. Ha a programozó tudja, hogy az adatra egyelőre nem lesz szükség, akkor 2 új utasítást használhat a kiíratására. Így lehetővé válik, hogy az adat nem foglalja a helyet a tárban.
Alaphelyzetben a CPU a különálló bájtok írásakor nem fordul külön-külön a memóriához, illetve a gyorsítótárhoz. Van egy néhány bájtos tárolója, amiben összegyűjti az íráskéréseket, majd egyszerre végrehajtja őket. Ameddig ez a tároló be nem telik, addig az olvasáskérések megelőzhetik az íráskéréseket. Egy új utasítással a CPU még a betelte előtt az írás végrehajtására kényszeríthető, illetve arra, hogy eközben ne engedje előre a később érkezett olvasás műveleteket.
Természetesen a megfelelő használatához a programnak érzékelnie kell, hogy használhatja-e az új utasításkészletet. Ebben segít a CPUID utasítás, melynek segítségével le lehet kérdezni a 3DNow! Jelenlétét a processzorban.
SSE (Streaming SIMD Extension)
Az Intel a maga lebegőpontos számokkal dolgozó utasításkészlet kiegészítését a fejlesztése alatt még Katmainak New Instructions-nak (KNI) nevezte. A Pentium III-mal vezette be. Az SSE 50 lebegőpontos számokra vonatkozó és 12 egész számra vonatkozó utasításból áll, ez utóbbiak szintén az MMX-et fejlesztik tovább, és az MMX-regiszterekkel dolgoznak.
A lebegőpontos számoknak az SSE nyolc új 128-bites regisztert (XMM0-XMM7) is hozott, ezekbe is 32-bites, egyszeres pontosságú előjeles számokat lehet elhelyezni, egyszerre négyet egy-egy XMM regiszterbe, vagyis a hagyományos lebegőpontos utasításokhoz képest négyszeresére nő a műveleti sebesség. Ez a regiszterkészlet nincs kapcsolatban a hagyományos lebegőpontos regiszterekkel, mint az MMX regiszterek, tehát a lebegőpontos SIMD-utasításokat keverni lehet az MMX-es és hagyományos lebegőpontos műveletekkel. Ugyanakkor az MMX-est nem lehet a lebegőpontos műveletekkel összekeverni.
A 3DNow! Továbbfejlesztésével kapcsolatban már említett gyorsítótárkezelő utasításokat az SSE is magába foglalja.
Az Intel fejlesztőmérnökei további utasításokkal egészítették ki az SSE-t. Az SSE2 egyelőre csak a Pentium 4-es processzorokban található meg. Az utasítások száma növekedett jelentősen. A 144 új utasítás került bevezetésre, illetve új adattípusok is támogatásra kerültek.
Az SSE2 128-bites egész, vagy 128-bites dupla pontosságú adatokon végezhetünk 144-féle utasítást.
Az SSE2 kiegészítés követi az SSE3, ami az Intel Prescott magos processzoraihoz lett kifejlesztve. Olyan új utasításokat tartalmaz, melyek igazodnak a programok igényeihez.

Visszalépéshez kattints a képre!